


Expertise in Deploying AI to Edge Devices
Darwin Edge has built up the skills and expertise to efficiently and accurately execute AI algorithms on edge devices working within the power and computational resource constraints.
We understand the challenges involved in deploying Edge AI
Several factors need to be considered while deploying an AI/ML algorithm on devices, e.g., how much model compression can be achieved, as well as the characteristics of the underlying hardware device and its supported platform(s).
Model Design
The goal is to reduce the model’s inference time on the device. Deep Neural Networks (DNNs) often require storing and accessing a large number of parameters that describe the model architecture. We thus need to design DNN architectures with reduced number of parameters. SqueezeNet is a good examples of efficient DNN architecture, optimized for Computer Vision use-cases. Neural Architecture Search (NAS) can also be used to discover edge efficient architectures.
Model Compression
Edge devices have limitations not only in terms of computational resources, but also memory. There are mainly two ways to perform NN compression: Lowering precision and fewer weights (pruning). By default, model parameters are float32 type variables, which lead to large model sizes and slower execution times. Post-training quantization tools, e.g., TensorFlow Lite, can be used to reduce the model parameters from float32 bits to unit8, at the expense of (slightly) lower precision. Pruning works by eliminating the network connections that are not useful to the NN, leading to reduction in both memory and computational overhead.
Device Specifications
ML/DL algorithms are characterized by extensive linear algebra, matrix and vector data operations. Traditional processor architectures are not optimized for such workloads, and hence, specialized processing architectures are necessary to meet the low latency requirements of running complex ML algorithm operations. As such, factors to be considered while choosing the edge device include balancing the model architecture (accuracy, size, operation type) requirements with device programmability, throughput, power consumption and cost.
Darwin Edge enables the full potential of Edge AI with the latest AI/ML techniques:
Computer Vision
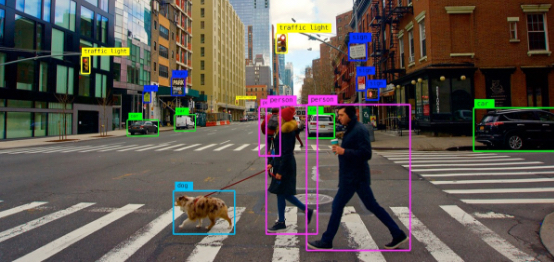
Computer Vision (CV) platforms have considerably matured over the last few years. This has been enabled by the advent of Deep Learning, e.g., Convolutional Neural Network (CNN) based architectures that allow extracting meaningful and contextual insights from given images. This has enabled many enterprise applications, such as, image classification, object recognition, semantic segmentation, sentiment analysis (based on facial images) and text extraction (Optical Character Recognition).
Predictive Analytics
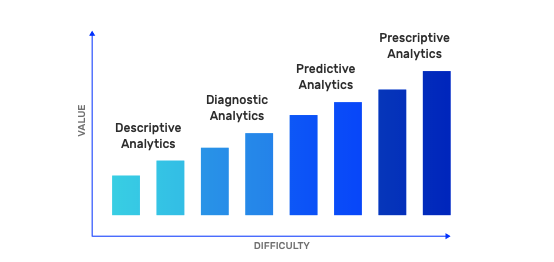
Predictive Analytics models and tools allow optimizing production (e.g., demand forecasting) and maintenance (e.g., predictive maintenance) decisions through more efficient understanding of patterns in current and historical data.
Together with Descriptive (“what happened?”), Diagnostic (“why it happened?”), and Prescriptive Analytics (“what can we do about it?”), Predictive Analytics (“what is likely to happen?”) provides the full set of enterprise analytical capabilities to get actionable insights from data.
We focus on Edge (AI) Analytics that enables the above analytical capabilities to be deployed on a sensor, device, or nearby node. With the widespread adoption of Internet of Things (IoT) and connected devices, many industries, such as, automotive, manufacturing and energy, are producing large amounts of data at the edge of the network. Edge Analytics then is basically data analytics in real-time and on-site, close to where the data is generated.
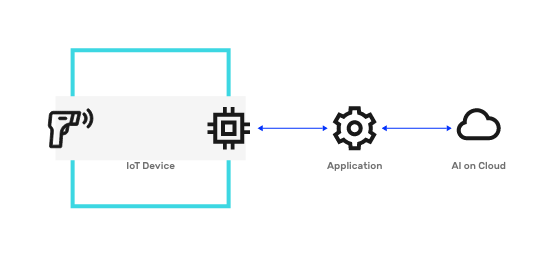
Edge Inference
Edge AI, or TinyML, leverages the fact that training and deployment processes for a Machine Learning (ML) model are completely decoupled. It allows a trained ML model to be embedded in devices with limited memory and computational resources — enabling their execution in a privacy preserving and offline fashion.
While ML models have traditionally been embedded in cameras, mobiles, drones, self-driven cars, etc., the growing adoption of Edge AI has led to the development of specialized devices capable of performing AI inferencing efficiently, e.g., Nvidia Jetson Nano, Google Coral, AWS DeepLens. Benchmarking results show 30 times performance gain running a Computer Vision model (MobileNet) on a generic Raspberry PI vs. specialized Nvidia Jetson.
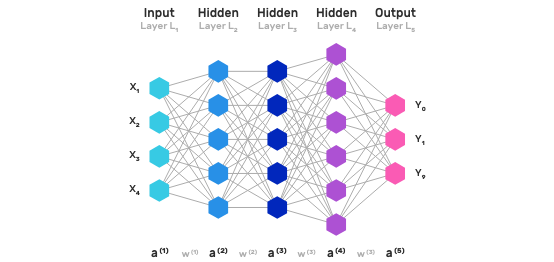
Deep Learning
Most of today’s Machine Learning (ML) models are supervised and applied on a prediction/classification task. Given a dataset, the Data Scientist has to go through a laborious process called feature extraction and the model’s accuracy depends entirely upon the Data Scientist’s ability to pick the right feature set.
The advantage of DL is that the program selects the feature set by itself without supervision, i.e. feature extraction is automated. This is achieved by training large-scale neural networks, referred to as Deep Neural Nets (DNNs) over large labeled datasets.
DL networks have shown ground breaking results achieving almost human-level performance for many Computer Vision and Natural Language Processing (NLP) tasks.
Reinforcement Learning
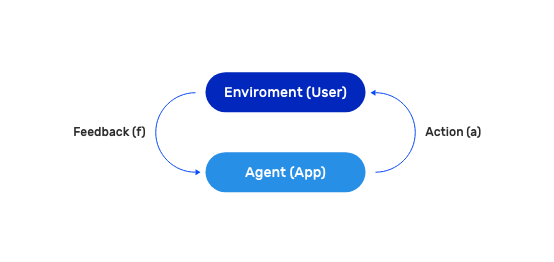
RL refers to a branch of Artificial Intelligence (AI), which is able to achieve complex goals by maximizing a reward function in real-time. The reward function works similar to incentivizing a child with candy and spankings, such that the algorithm is penalized when it takes a wrong decision and rewarded when it takes a right one — this is reinforcement. The reinforcement aspect also allows it to adapt faster to real-time changes in the user sentiment. RL is a good fit for industrial control systems as it is able to learn and adapt to multi-parameterized system dynamics in real-time, without requiring any knowledge of the underlying system model.
Federated Learning
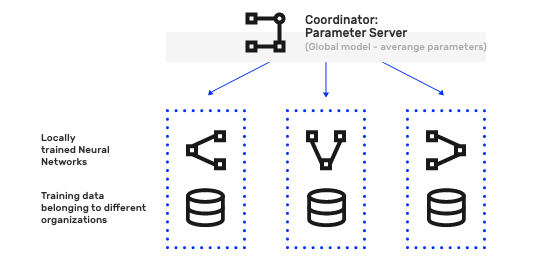
Federated learning, also known as Collaborative Learning, or Privacy preserving Machine Learning, enables multiple entities who do not trust each other (fully), to collaborate in training a Machine Learning (ML) model on their combined dataset; without actually sharing data — addressing critical issues such as privacy, access rights and access to heterogeneous confidential data.
This is in contrast to traditional (centralized) ML techniques where local datasets (belonging to different entities) need to be first brought to a common location before model training. Its applications are spread over a number of industries including defense, telecommunications, healthcare, advertising and Chatbots.
Learn how you can benefit from our Edge AI expertise.
Request info