



Edge AI: Framework for Healthcare Applications

Daniel Kaempf May 25, 2021
Deploying AI/ML models on Edge Devices
Debmalya Biswas
Mar 25 · 11 min read
(Darwin Edge, Switzerland) Miljan Vuletić, Vladimir Mujagić, Marko Atanasievski, Nikola Milojević, Debmalya Biswas
Abstract. Edge AI enables intelligent solutions to be deployed on edge devices, reducing latency, allowing offline execution, and providing strong privacy guarantees. Unfortunately, achieving efficient and accurate execution of AI algorithms on edge devices, with limited power and computational resources, raises several deployment challenges. Existing solutions are very specific to a hardware platform/vendor. In this work, we present the MATE framework that provides tools to (1) foster model-to-platform adaptations, (2) enable validation of the deployed models proving their alignment with the originals, and (3) empower engineers and architects to do it efficiently using repeated, but rapid development cycles. We finally show the practical utility of the proposal by applying it on a real-life healthcare body-pose estimation app.
This paper has been accepted for presentation at the 4th IJCAI Workshop on AI for Ageing, Rehabilitation and Intelligent Assisted Living (ARIAL), Montreal, Aug 2021 (pdf)
1. Introduction
Edge AI, also known as TinyML, aims to bring all the goodness of AI to the device. In its simplest form, the device is able to process the data locally and instantaneously, without any dependency on the Cloud.
Edge AI enables Visual, Location and Analytical solutions at the edge for diverse industries, such as Healthcare, Automotive, Manufacturing, Retail and Energy.
According to a report by Market and Markets (Markets & Markets, 2020), “the global Edge AI software market size is expected to grow to USD 1835 million by 2026”. Similarly, a report by 360 Research Reports (360 Research, 2019) estimates that “the global Edge AI Software market size will reach US$ 1087.7 million by 2024”.
Edge AI leverages the fact that training and deployment processes for a Machine Learning (ML) model are completely decoupled. It allows a trained ML model to be embedded in devices with limited memory and computational resources — enabling their execution in an offline fashion. The key Edge AI benefits are as follows:
- Low Latency (Offline execution): Running AI models on the Cloud means a round-trip latency of at least few milliseconds, which can potentially go up to a few seconds depending on network connectivity. Unfortunately, this is not sufficient for real-time decision making, e.g., automated cars at high-speed, robots monitoring elderly people, or those working alongside people at factory assembly lines. While network connectivity is often taken for granted in an enterprise setting, the same cannot be said for factories in remote areas or drones flying at high altitudes over unmapped territories. Deploying the underlying models on the edge ensures that they can run offline in (near) real-time.
- Privacy: Processing data locally, on the device itself, implies that we do not need to send it back to the Cloud for processing. This becomes increasingly relevant as smart devices (e.g., cameras, speakers) start getting deployed in shops, hospitals, offices, factories, etc., coupled with growing user distrust pertaining to how enterprises are storing and processing their personal data, including images, audio, video, location and shopping history. In addition, storing data in any form always raises the risk of potential hacks and cyberthefts.
- Reduce Costs: Real-time processing at the edge not only enables low latency and privacy protection, but it also acts as a ‘filter’ ensuring that only relevant data gets transmitted to the Cloud for further processing — saving bandwidth. Less data transferred to the Cloud, also implies less storage and processing costs on the Cloud. Processing data on the Cloud can be quite expensive, esp. when it is in the order of gigabytes (link) or petabytes (link) per day.
While ML models have traditionally been embedded in cameras, mobiles, drones, self-driven cars, etc., the growing adoption of Edge AI has led to the development of specialized devices capable of performing AI inferencing efficiently, e.g., Nvidia Jetson Nano, Google Coral, AWS DeepLens. Benchmarking results (Haiges, 2020) show 30 times performance gain running a Computer Vision model (MobileNet) on a generic Raspberry PI vs. specialized Nvidia Jetson.
Unfortunately, deploying ML models on edge devices still remains a very challenging task. In particular, the following factors need to be considered while designing an Edge AI solution (Xu et al., 2020; Plastiras et al., 2018; Merenda et al., 2020):
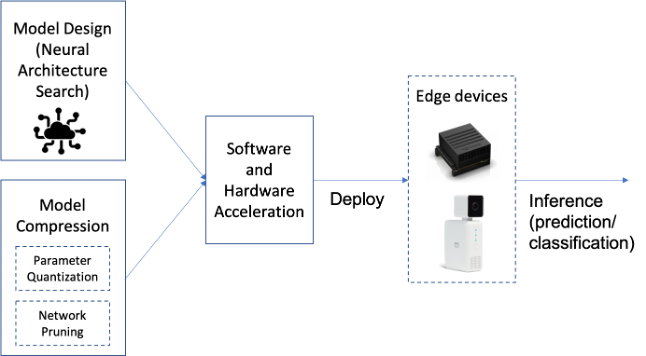
- Model design: The goal is to reduce the model’s inference time on the device. Deep Neural Networks (DNNs) often require storing and accessing a large number of parameters that describe the model architecture. We thus need to design DNN architectures with reduced number of parameters. SqueezeNet is a good examples of efficient DNN architecture, optimized for Computer Vision use-cases. Neural Architecture Search (NAS) can also be used to discover edge efficient architectures.
- Model compression: Edge devices have limitations not only in terms of computational resources, but also memory. There are mainly two ways to perform NN compression: Lowering precision and fewer weights (pruning). By default, model parameters are float32 type variables, which lead to large model sizes and slower execution times. Post-training quantization tools, e.g., TensorFlow Lite, can be used to reduce the model parameters from float32 bits to unit8, at the expense of (slightly) lower precision. Pruning works by eliminating the network connections that are not useful to the NN, leading to reduction in both memory and computational overhead.
- Device considerations: ML/DL algorithms are characterized by extensive linear algebra, matrix and vector data operations. Traditional processor architectures are not optimized for such workloads, and hence, specialized processing architectures are necessary to meet the low latency requirements of running complex ML algorithm operations. As such, factors to be considered while choosing the edge device include balancing the model architecture (accuracy, size, operation type) requirements with device programmability, throughput, power consumption and cost.
To address these challenges, we present the Model Audit Towards Endorsement (MATE) framework (Section 2.2) that provides necessary tools and processes for rapid deployment of AI/ML research results into AI aware applications on edge devices.
MATE provides: (1) extensible inference engines, (2) platform independent libraries supporting image transformations, and (3) validation tools capable of guaranteeing the algorithm functionality across different platforms. In Section 3, we illustrate the use of the proposed flows and methodologies on a concrete use case of a Healthcare-AI application deployed to a camera-equipped embedded platform. We discuss the benefits of the approach, demonstrate its configurability to support different business scenarios, and propose directions for future improvements (Section 4).
2. Rapid Edge AI Prototyping and Deployment
2.1 Bonseyes
The proposed MATE framework stems from our work and experience with the Bonseyes EU project. The project aims to develop a platform consisting of a Data (AI) Marketplace, a Deep Learning Toolbox, and Developer Reference Platforms for organizations wanting to adopt AI in low power IoT devices, embedded computing systems, or data center servers.
To ease and unify the build and development process, Bonseyes provides Developer Reference Platforms which implement build managers with a cross compilation environment. They are downloaded as docker images, and can be tailored for specific platform(s). Usually, C++/Python software with dependencies to QT, OpenCV, GStreamer or Vulkan (if the target platform has a GPU device) could be easily built out of the box. After build, the built binaries can be copied, e.g., to a target Jetson Xavier platform and run. It is possible to purchase another Developer Platform from the AI Marketplace and use the same build to execute another build docker and build the application, e.g., for NXP IMX8, Nvidia Jetson Nano or Raspberry Pi target boards.
This alleviates the challenges associated with classic application port experience. For an application to be built for Jetson Xavier platform on a classic Ubuntu desktop environment, we would need to manually set a cross compilation environment, which includes installing target compiler, reproducing the exact system root that is running on board (system and application library versions, driver versions). For some more complex use cases (Jetson Xavier has CUDA environment, driver and tools) we would need to reverse engineer CUDA library packages and versions. Setting up a reproducible build environment for some target boards could take days, even weeks.
2.2 MATE Framework
Figure 1 presents a high-level overview of the Edge AI deployment pipeline.
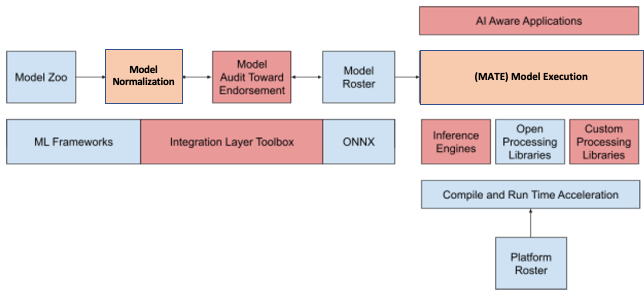
Model Zoo consists of published AI/ML research accessible through research community platforms, e.g., Papers with Code. They are usually built using typical ML frameworks, e.g., PyTorch, Keras, Caffe, scikit-learn; often based on Python-backed ecosystems and packages, e.g., TensorFlow, Theano, NumPy, SciPy, OpenCV. We select models corresponding to our embedded application requirements from the Zoo and add an adaptation layer upon them — exposing their functionality to our tools from the integration framework.
Model Normalization includes adapting a chosen model to provide a standard interface towards the Integration Layer tools.
The interface exposes basic functionality indispensable for training, evaluation and validation of the model: a normalized model preserves its original functionality and yet makes it accessible to our flow. The normalized model is ready to be scrutinised by MATE (Model Audit Toward Endorsement).
MATE is a central component of our development flow. It allows for rapid prototyping and deployment, facilitating the search for optimal configurations within the entire design space.
Figure 2 depicts the core MATE tools as a foundation for supporting processes of model evaluation and validation.
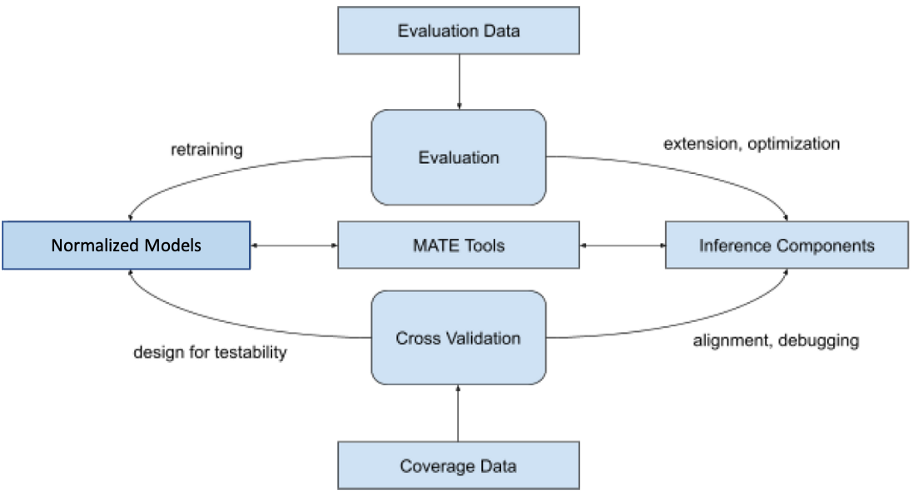
MATE can access normalized models through the standard interface and run evaluation of the models using their original framework, usually running on a workstation or in the Cloud. It can also run their corresponding embedded platform implementation built using Inference Components, including our inference engine and custom processing libraries.
The evaluation process may lead to retraining of the models. It may also provide recommendations in terms of the necessary extensions and optimizations on the embedded platform side. For example, retraining can be triggered to improve model evaluation on in-field-collected data: public models are usually trained on general datasets and may require fine-tuning for the special scenarios in a particular field of application. As mentioned, model quantization for speeding up the model execution on embedded devices can be another reason for model retraining. On the platform side, the evaluation process shows which layers are to be added and optimized in our inference engine; pre and post-processing libraries are also updated to be aligned with the original models.
Inference Components provide a cross-compilation environment and tooling that is capable of creating executables for the target hardware on the developer workstation. In this way,
we harness the error-prone tasks of architectural changes and optimizations on both sides and safeguard their perfect alignment and consistency.
The process also drives improving the design for testability and helps us in debugging and alignment. Once we are satisfied with performance and size of the model platform implementation, we put the model to Model Roster, i.e., models and their accompanying configurations guaranteed to run on different platforms from the embedded Platform Roster. Choosing the appropriate configuration is crucial to achieving the desired performance on platforms chosen for the final application, and we are currently in the process of automating this task.
3. Edge AI Use-case — Body Pose Estimation
In this section, we illustrate our approach with a real-life application — Kestrel. The app monitors patients in their beds and signals an alarm if some of the patients fell off the bed which may be a big problem for the residents of hospitals and old-age homes. The development included the selection of state-of-the-art object detection algorithms for face-landmarks and body pose detection, esp. RetinaFace (Deng et al., 2019) and OpenPifPaf (Kreiss et al., 2021); and porting them to the Nvidia Jetson NX platform (Fig. 3).
Figure 3. Nvidia Jetson NX platform with a camera (Image by Authors)
The Nvidia platform is an affordable embedded platform with remarkable computing support for AI, including GPUs and DLAs (Deep Learning hardware Accelerators). The AI computing resources are exposed to programmers through the Nvidia TensorRT library.
In order to normalize the models, we have applied the methodology presented in the previous section, using several development phases: initial evaluation; check of the pre and post processing compatibility with our libraries; missing layers identification; missing layer implementation; inference, pre-processing, and post-processing cross-validation; and eventually the benchmarking.
Through the process, we have leveraged the existence of common layers in both architectures: after implementing missing layers from the first architecture to our framework, we have integrated the second architecture in much less time. We have also been able to share some of the pre-processing steps for both applications. In order to be able to access the DLA acceleration, we have integrated the TensorRT library into our framework beneath a unifying inference-engine access layer. It is only a choice of configuration that determines whether the application shall use TensorRT-based inference or the framework custom inference engine. The overall development took from 2 to 3 engineering months per application. Without MATE tools, our estimation is that the time would be significantly longer. Another thing to notice is that the obtained applications are now easily portable across all the platforms that our framework supports.
Fig. 4 below provides illustrations of the algorithms execution on sample videos from a possible field of application (e.g., detecting elderly people state and position). For the purpose of the experiments, we have packaged the models into deployable applications, both with custom-developed application layers.

4. Conclusion
In this work, we presented a set of tools to prototype, port, and validate AI models in a hardware/platform agnostic fashion; and run them on edge devices. In future, we plan to add configuration automation, for finding optimal deployment set-up within given execution constraints. We also aim to extend support for compile-time optimizations of the inference process, allowing us to target cheaper and less power hungry devices.
References
- 360 Research. Global Edge Software Market Growth (Status and Outlook) 2019–2024, 2019. URL https://www.360researchreports.com/global-edge-ai-software-market-14355998.
- Deng, J., Guo, J., Zhou, Y., Yu, J., Kotsia, I., and Zafeiriou, S. RetinaFace: Single-stage Dense Face Localisation in the Wild. arXiv, abs/1905.00641, 2019.
- Haiges, S. AI on the Edge: what use cases it enables and how to start learning about it!, 2020. https://bit.ly/2NSiOUY.
- Kreiss, S., Bertoni, L., and Alahi, A. OpenPif-Paf: Composite Fields for Semantic Keypoint Detection and Spatio-Temporal Association. arXiv, abs/2103.02440, 2021.
- Markets and Markets. Edge AI Software Market, 2020. https://www.marketsandmarkets.com/Market-Reports/edge-ai-software-market-70030817.html
- Merenda, M., Porcaro, C., and Iero, D. Edge Machine Learning for AI-Enabled IoT Devices: A Review. Sensors, 20(9), 2020. ISSN 1424–8220. doi:10.3390/s20092533. https://www.mdpi.com/1424–8220/20/9/2533.
- Plastiras, G., Terzi, M., Kyrkou, C., and Theocharidcs, T. Edge Intelligence: Challenges and Opportunities of Near-Sensor Machine Learning Applications. In IEEE 29th International Conference on Application-specific Systems, Architectures and Processors (ASAP), pp. 1–7, 2018. doi: 10.1109/ASAP.2018.8445118.
- Xu, D., Li, T., Li, Y., Su, X., Tarkoma, S., Jiang, T., Crowcroft, J., and Hui, P. Edge Intelligence: Architectures, Challenges, and Applications. arXiv, abs/2003.12172, 2020.
