



Edge AI: Deploying AI/ML on Edge Devices

Daniel Kaempf May 31, 2021
Challenges in deploying Edge AI applications
Introduction
AI/ML use-cases are pervasive. The enterprise use-cases can be broadly categorized based on the three core technical capabilities enabling them: Predictive Analytics, Computer Vision (CV) and Natural Language Processing (NLP). The Enterprise AI story has so far been focused on the Cloud. The general perception is that it takes a large amount of data and powerful machines, e.g., Graphical Processing Units (GPUs), to run AI applications.
Edge AI, also known as TinyML, aims to bring all the goodness of AI to the device. The idea is to bring the processing as close as possible to the devices generating the data.
In its simplest form, the device is able to process the data locally and instantaneously, without any dependency on the Cloud. Edge AI enables Visual, Location and Analytical solutions at the edge for diverse industries, such as Healthcare, Automotive, Manufacturing, Retail and Energy. According to a report by Market and Markets, “the global Edge AI software market size is expected to grow to USD 1,835 million by 2026”. Similarly, a report by 360 Research Reports estimates that “the global Edge AI Software market size will reach US$ 1087.7 million by 2024”.
The key Edge AI benefits are as follows:
- Low Latency / Offline execution: Running AI models on the Cloud means a round-trip latency of at least few milliseconds, which can potentially go up to a few seconds depending on network connectivity. Unfortunately, this is not sufficient for real-time decision making, e.g., automated cars at high-speed, robots monitoring elderly people, or those working alongside people at factory assembly lines. While network connectivity is often taken for granted in an enterprise setting, the same cannot be said for factories in remote areas or drones flying at high altitudes over unmapped territories. Deploying the underlying models on the edge ensures that they can run offline in (near) real-time.
- Privacy: Processing data locally, on the device itself, implies that we do not need to send it back to the Cloud for processing. This becomes increasingly relevant as smart devices (e.g., cameras, speakers) start getting deployed in shops, hospitals, offices, factories, etc., coupled with growing user distrust pertaining to how enterprises are storing and processing their personal data, including images, audio, video, location and shopping history. In addition, storing data in any form always raises the risk of potential hacks and cyberthefts.
- Reduce Costs: Real-time processing at the edge not only enables low latency and privacy protection, but it also acts as a ‘filter’ ensuring that only relevant data gets transmitted to the Cloud for further processing — saving bandwidth. Less data transferred to the Cloud, also implies less storage and processing costs on the Cloud. Processing data on the Cloud can be quite expensive, esp. when it is in the order of gigabytes (link) or petabytes (link) per day.
Internals: Training vs. Deployment
Most of today’s ML models are supervised and applied on a prediction or classification task. Given a training (labeled) dataset, the Data Scientist has to go through a laborious process called feature extraction and the model’s accuracy depends entirely upon the Data Scientist’s ability to pick the right feature set. For simplicity, each feature can be considered a column of a dataset provided as a CSV file. The advantage of DL is that the program selects the feature set by itself without supervision, i.e. feature extraction is automated. This is achieved by training large-scale neural networks, referred to as Deep Neural Nets (DNNs) over large labeled datasets. Training a DNN occurs over multiple iterations (epochs). Each forward run is coupled with a feedback loop, where the classification errors identified at the end of a run with respect to the ground truth (training dataset) is fed back to the previous (hidden) layers to adapt their parameter weights — ‘backpropagation’.
It is important to understand that the training and deployment processes for a DL lifecycle are completely decoupled. During training, a large amount of data is used to calculate the model parameters (coefficients, weights and biases) — leading to the need for more resources. Once trained, the computed parameters can be persisted to storage (file), program memory (RAM), and deployed as an API. The deployed models are monitored for drift, and retrained as necessary.
Trained ML/DL models can be deployed as APIs that completely decouple the consumption from the training process. It also allows a trained ML/DL model to be embedded in devices with limited memory and computational resources — enabling their execution in an offline fashion.
Edge Devices
While ML models have traditionally been embedded in cameras, mobiles, drones, self-driven cars, etc., the growing adoption of Edge AI has led to the development of specialized devices capable of performing AI inferencing efficiently, e.g., Nvidia Jetson Nano, Google Coral, AWS DeepLens. Benchmarking results show 30 times performance gain running a Computer Vision model (MobileNet) on a generic Raspberry PI vs. specialized Nvidia Jetson.
Nvidia’s flagship product targeting Edge AI applications is based on Nvidia Jetson AGX Xavier module. The accompanying Nvidia Jetson AGX Xavier Developer Kit provides tools and libraries for development of Edge AI applications.
Major cloud vendors have collaborated with semiconductor companies to deliver AI chips.
Microsoft collaborated with Qualcomm to develop Vision AI DevKit. It uses Azure ML (with support for frameworks like TensorFlow, Caffe) to develop the models and Azure IoT Edge to deploy the models to the kit as containerized Azure services. The Qualcomm Neural Processing SDK helps in optimizing the models — further reducing latency and improving application performance efficiency.
In collaboration with Intel, Amazon developed DeepLens — a wireless camera with AI inferencing capabilities. It is integrated with Amazon SageMaker, which is Amazon’s primary Data Science platform. This allows ML models to be trained on SageMaker with support for different ML/DL frameworks, e.g., Scikit-learn, TensorFlow, PyTorch and Amazon’s own MXNet, and then to be deployed on DeepLens in an integrated fashion.
Google has also entered the field recently with their Coral range of products. The underlying hardware is Google’s Edge Tensor Processing Units (TPUs). Coral provides the full toolkit to train TensorFlow models and deploy them on different platforms using the Coral USB Accelerator. Coral’s key differentiator, which can also be considered as its main drawback, is its tight integration with Google’s cognitive ecosystem, such that its Edge TPU-powered hardware only works with Google’s ML/DL framework, TensorFlow.
Embedded Hardware Considerations
Depending on the task, both ML algorithms, e.g., K-nearest neighbours (K-NN), Support Vector Machines (SVMs) and Tree-based algorithms, and Deep Neural Networks, e.g., Convolutional Neural Networks (CNNs), Recurrent Neural networks (RNNs); can be considered for deployment on edge devices.
The choice of ML algorithms often depends on the algorithm internals, e.g., how much model compression can be achieved, as well as the characteristics of the underlying hardware device and its supported platform(s).
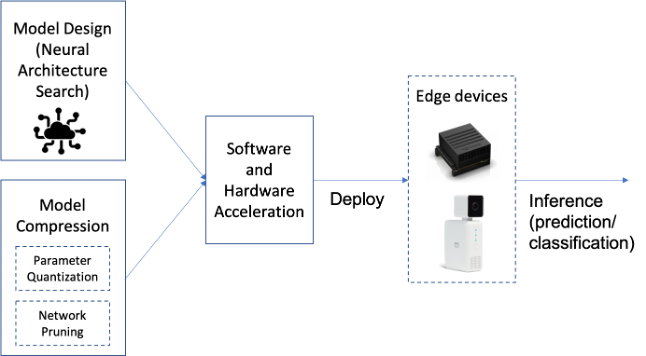
In particular, the following factors need to be considered while designing an Edge AI solution:
- Model design: The goal is to reduce the model’s inference time on the device. Deep Neural Networks (DNNs) often require storing and accessing a large number of parameters that describe the model architecture. We thus need to design DNN architectures with reduced number of parameters. SqueezeNet is a good examples of efficient DNN architecture, optimized for Computer Vision use-cases. Neural Architecture Search (NAS) can also be used to discover edge efficient architectures.
- Model compression: Edge devices have limitations not only in terms of computational resources, but also memory. There are mainly two ways to perform NN compression: Lowering precision and fewer weights (pruning). By default, model parameters are float32 type variables, which lead to large model sizes and slower execution times. Post-training quantization tools, e.g., TensorFlow Lite, can be used to reduce the model parameters from float32 bits to unit8, at the expense of (slightly) lower precision. Pruning works by eliminating the network connections that are not useful to the NN, leading to reduction in both memory and computational overhead.
- Device considerations: ML/DL algorithms are characterized by extensive linear algebra, matrix and vector data operations. Traditional processor architectures are not optimized for such workloads, and hence, specialized processing architectures are necessary to meet the low latency requirements of running complex ML algorithm operations. As such, factors to be considered while choosing the edge device include balancing the model architecture (accuracy, size, operation type) requirements with device programmability, throughput, power consumption and cost.
References
- Dianlei Xu, et. al. Edge Intelligence: Architectures, Challenges, and Applications. (link)
- M. Terzi, et. al. Edge Intelligence: Challenges and Opportunities of Near-Sensor Machine Learning Applications. (link)
- M. Merenda, et. al. Edge Machine Learning for AI-Enabled IoT Devices: A Review. (link)
- D. Moelker. When to Bring AI to the Edge. (link)
- What Is Edge AI And Why Should Enterprises Care? (link)
- B. Wilson. 5 Ways Edge AI Will Change Enterprises in 2021. (link)
- What is Edge AI, and Why Enterprises Should Care About It? (link)
- Y. Khan. How AI at the Edge Can Generate Enterprise-Wide Savings. (link)
